برازش منحنی به عملی گفته میشود که با کمک آن میتوان منحنیهای مختلف را از مجموعهای از نقاط عبور داد. مثلاً شما تعدادی دادهی آزمایشگاهی دارید و میخواهید بهترین منحنی با معادله مشخص و یا نامشخص را از این نقاط عبور دهید، به این کار برازش منحنی میگویند. در ادامه مطلب با ترفندها همراه باشید تا نرم افزارهایی جهت برازش منحنی به شما معرفی کنیم.
نرم افزار های مورد استفاده جهت برازش منحنی بسته به نوع دادهها (تعداد متغییرهای وابسته و مستقل) به دو دسته زیر تقسیم میشوند.
الف) نرم افزارهای برازش منحنی برای دادههای با ۱ متغیر وابسته و ۱ متغییر مستقل (2D)
۱) نرم افزار اکسل
برای این کار میتوانید از قابلیت Trend Line موجود در نرم افزار اکسل که قبلا در این مطلب شرح داده شده است استفاده کنید.
۲) نرم افزار CurveExpert Basic
این نرم افزار دارای تعداد زیادی مدل رگرسیون خطی و غیر خطی و روشهای مختلف درونیابی میباشد. همچنین امکان تعریف مدلهای رگرسیون توسط کاربر پیش بینی شده است. تعداد نقاط دادهای قابل تعریف در این نرم افزار نامحدود می باشد. نقاط دادهای را می توان مستقیماً وارد نمود. علاوه بر این امکانات ویژهای برای وارد نمودن دادهها از انواع فایلهای مختلف در نظر گرفته شده است که بطور هوشمند میتواند توضیحات و متون را از نقاط دادهای تشخیص دهد. علاوه بر امکانات گرافیکی مناسب، قابلیتهای تحلیلی از جمله محاسبه مشتق و انتگرال در نظر گرفته شده است.
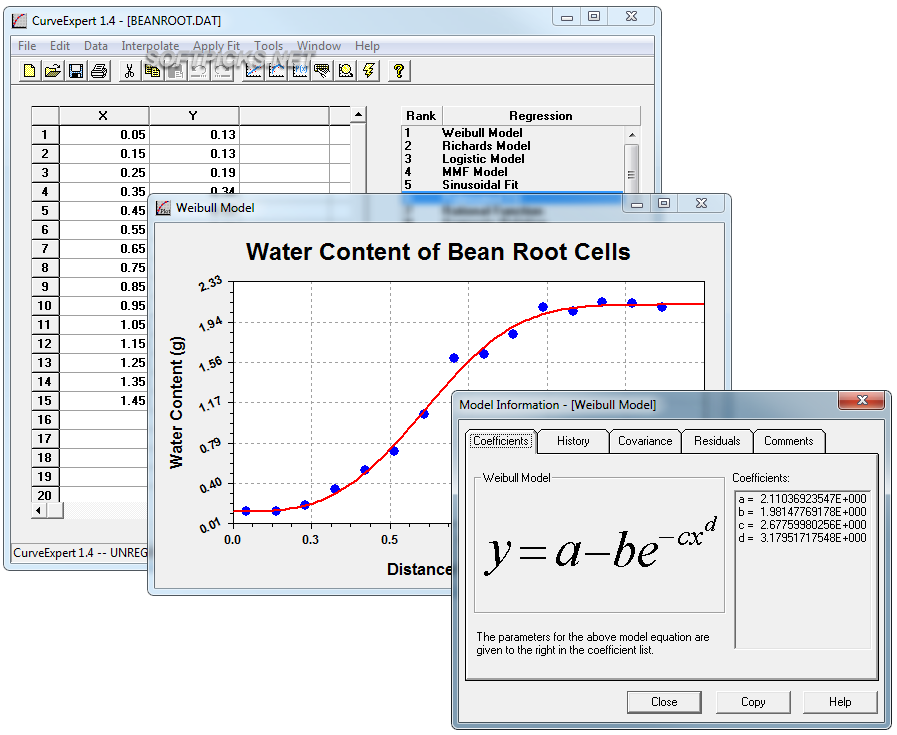
راهنمای استفاده از این نرم افزار را از اینجا دانلود کنید. همچنین ویدئوی آموزشی زیر را نیز میتوانید مشاهده کنید.
دریافت
مدت زمان: 4 دقیقه 48 ثانیه
منبع: tebyan.net
۳) نرم افزار Table Curve 2D. ver 5.01 (لینک کمکی نسخه 30 روزه)
این نرم افزار نیز برای برازش دو بعدی کاربرد دارد. راهنمای استفاده از این نرم افزار را از اینجا دانلود کنید.
راهنمای فعال سازی:
پس از نصب و اجرای نرم افزار در پنجره License information بر روی گزینه Update کلیک نموده و سپس شماره سریال 45DA09CE-FBFB1907 وارد کنید.
نکته: اگر در ابتدای اجرای برنامه پنجره ی مورد به هر دلیلی نمایش داده نشد می توانید پس از وارد شده به محیط برنامه از مسیر Tools-->chose update product license به پنجره لایسنس دسترسی پیدا کنید.

۴) نرم افزار تخصصی متلب (Matlab)
نرمافزار متلب به شما اجازهی انتخاب هر نوع معادلهای را میدهد و شما با انتخاب نوع معادله و ورود دادهها به نرمافزار میتوانید ضرایب معادله مورد نظر خود را بدست آورید. در اینجا به صورت تصویری، چگونگی برازش منحنی یا کرو فیتینگ (Curve Fitting) در نرمافزار متلب را توضیح داده شده است.
ب) نرم افزارهای برازش منحنی برای دادههای با ۱ متغیر وابسته و ۲ یا چند متغییر مستقل (3D)
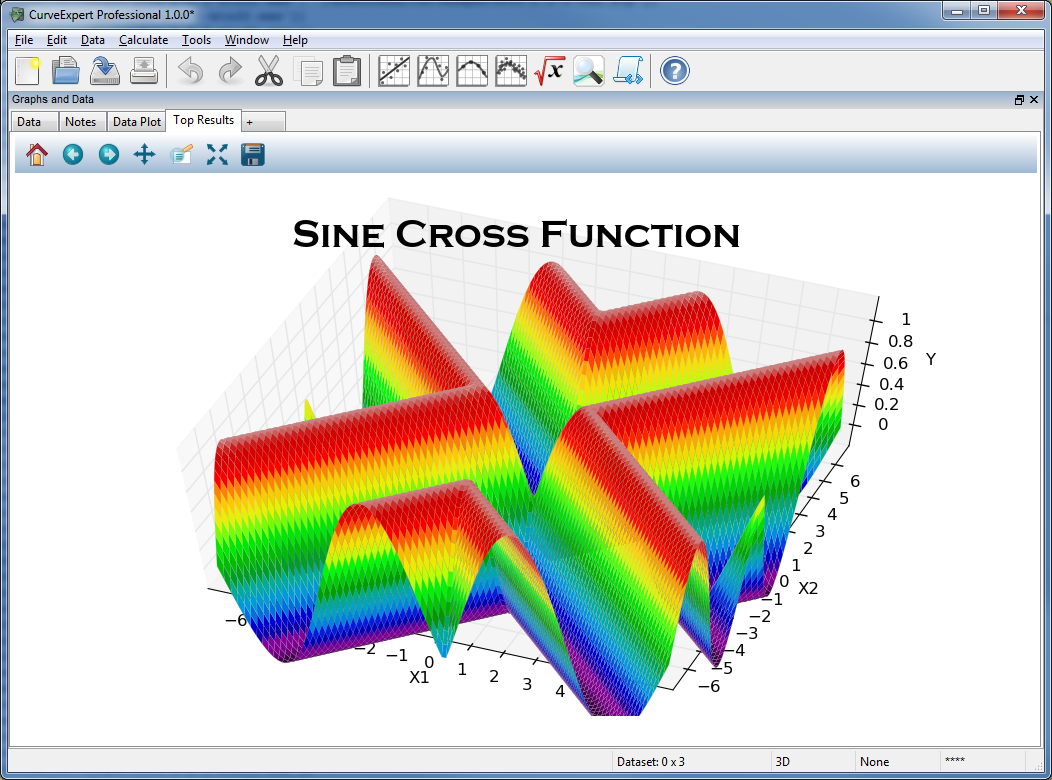
۱) نرم افزار CurveExpert Professional
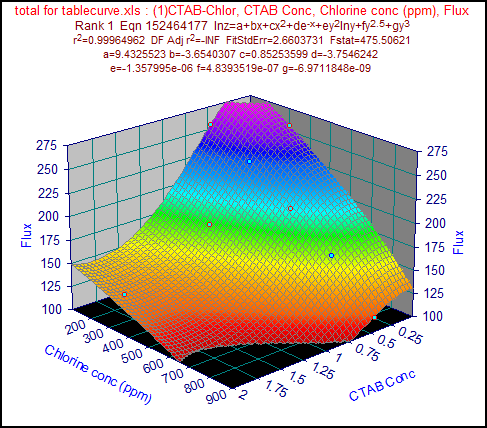
۲) نرم افزار Table Curve 3D. ver 4.0 (لینک کمکی نسخه 30 روزه)
راهنمای فعال سازی:
پس از نصب و اجرای نرم افزار در پنجره License information بر روی گزینه Update کلیک نموده و سپس شماره سریال 2A7CF6F8-FBFB1907 وارد کنید.
نکته: اگر در ابتدای اجرای برنامه پنجره ی مورد به هر دلیلی نمایش داده نشد می توانید پس از وارد شده به محیط برنامه از مسیر Tools-->chose update product license به پنجره لایسنس دسترسی پیدا کنید.
نرم افزارهای دیگری نیز برای برازش منحنی وجود دارد از جمله:
۱- DataFit
۲-EasyFit
و ...




 2- در پنجره باز شده، از قسمت find گزینه more کلیک کنید.
2- در پنجره باز شده، از قسمت find گزینه more کلیک کنید.